Sensitive Data Identification
This feature is available on the StackHawk Enterprise plan.
Sensitive Data Identification analyzes your connected code repositories to detect references to regulated or sensitive data types. Repositories handling sensitive data are automatically flagged in the Attack Surface view, helping you identify which APIs should be prioritized for security testing.
How It Works
StackHawk analyzes source code directly in your connected repositories—no runtime traffic monitoring or manual tagging required.
- Automatic Detection: When you connect a repository, StackHawk scans the source code for patterns that indicate sensitive data handling
- Labeling: Detected data types appear as labels (PII, PCI, PHI) in the Attack Surface Table
- Continuous Updates: As your code changes, detection runs automatically to keep labels current
What We Detect
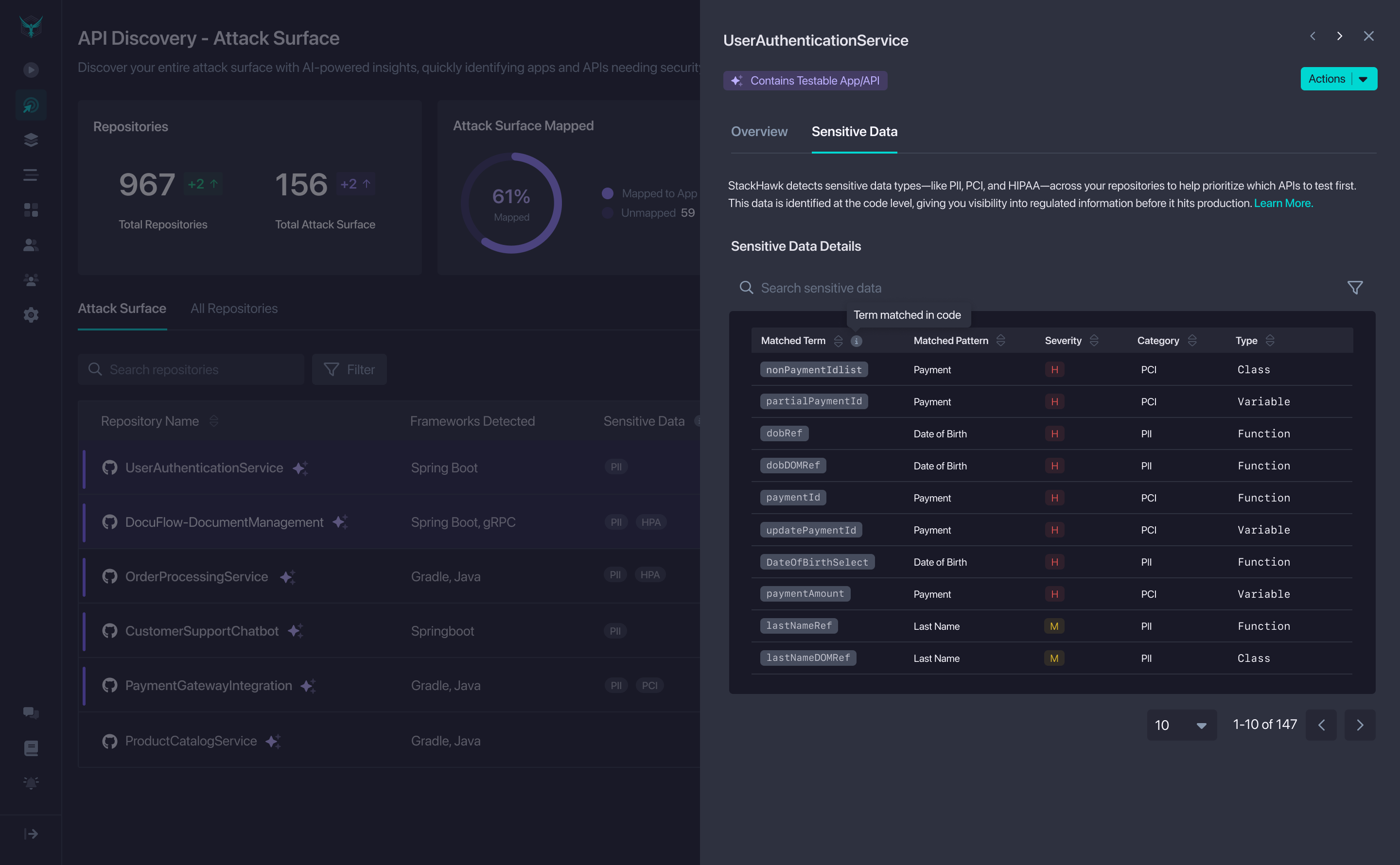
| Data Type | Description | Examples |
|---|---|---|
| PII | Personally Identifiable Information | Names, emails, addresses, phone numbers, SSNs |
| PCI | Payment Card Industry data | Credit card numbers, CVVs, payment tokens |
| PHI | Protected Health Information (HIPAA) | Medical records, health conditions, treatment data |
Using Sensitive Data Labels
Sensitive data labels appear in the Attack Surface Table alongside each repository.
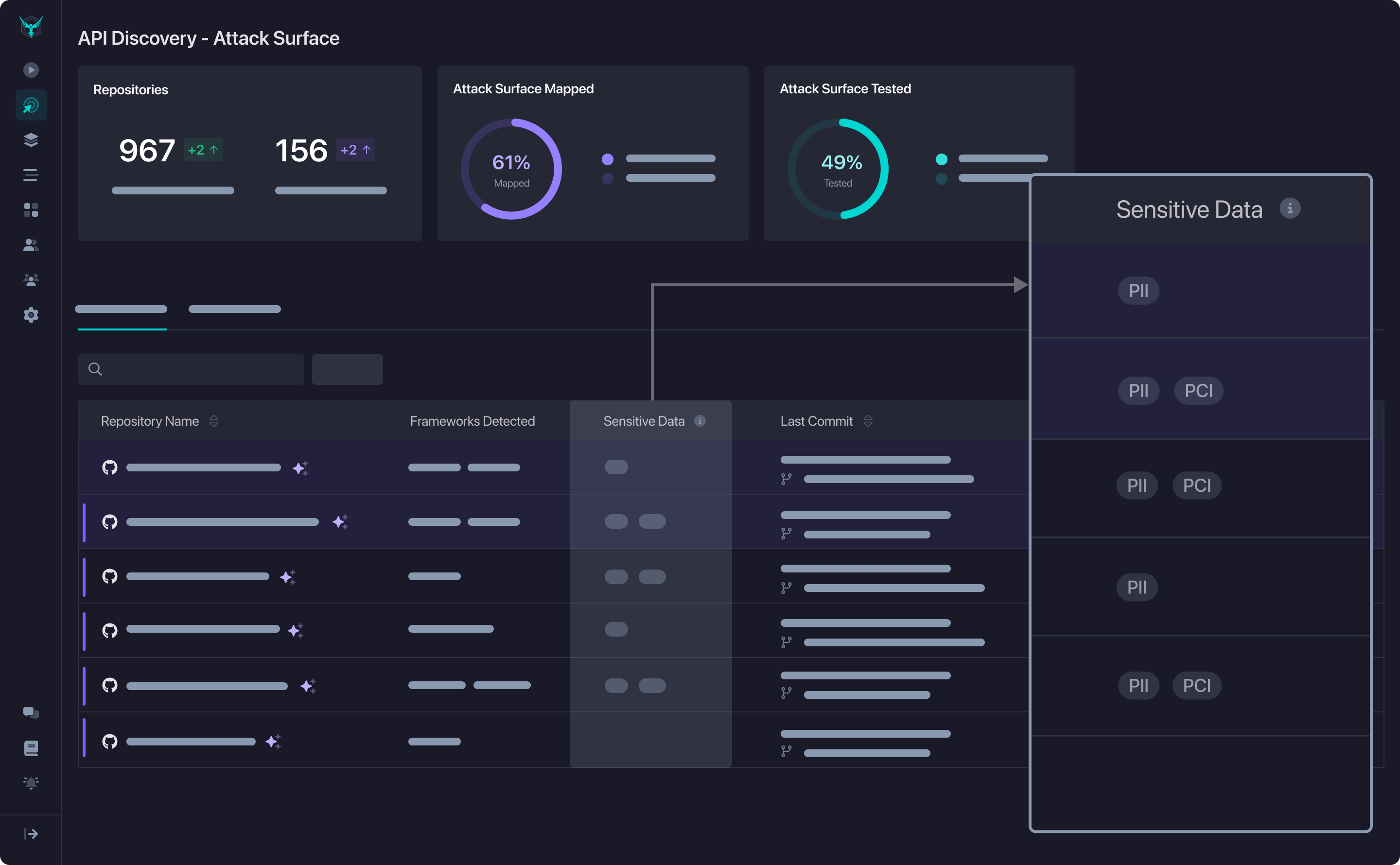
Use these labels to:
- Filter repositories by data type to focus on specific compliance requirements
- Prioritize testing for repositories handling regulated data
- Track coverage of sensitive systems across your organization
Click on a sensitive data label to view details about what was detected.
Supported Languages
Sensitive data identification is available for repositories written in:
- C#
- Go
- Java
- JavaScript
- Kotlin
- PHP
- Python
- Rust
- Scala
- TypeScript
If your repositories use a language not listed above, reach out to product@stackhawk.com.